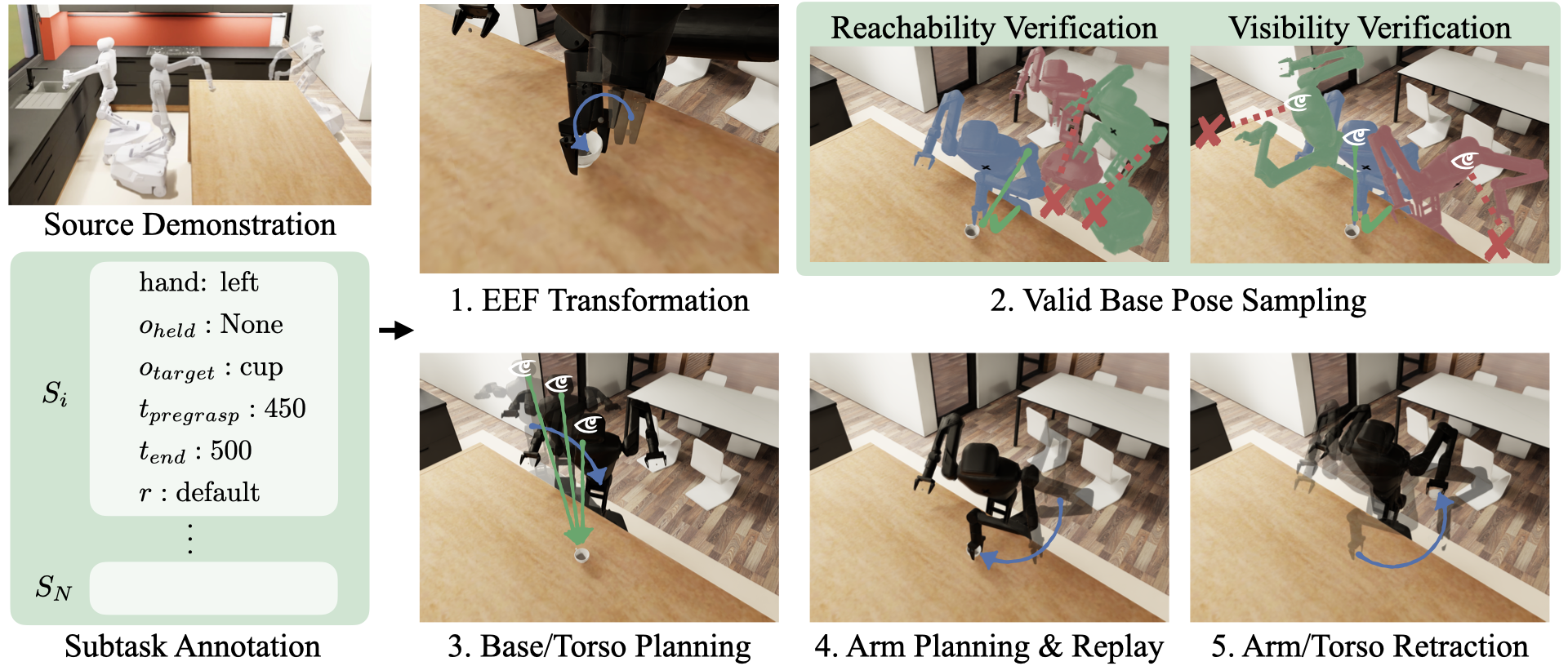
Imitation learning from large-scale, diverse human demonstrations has been shown to be effective for training robots, but collecting such data is costly and time-consuming. This challenge intensifies for multi-step bimanual mobile manipulation, where humans must teleoperate both the mobile base and two high-DoF arms. Prior X-Gen works have developed automated data generation frameworks for static (bimanual) manipulation tasks, augmenting a few human demos in simulation with novel scene configurations to synthesize large-scale datasets. However, prior works fall short for bimanual mobile manipulation tasks for two major reasons: 1) a mobile base introduces the problem of how to place the robot base to enable downstream manipulation (reachability) and 2) an active camera introduces the problem of how to position the camera to generate data for a visuomotor policy (visibility). To address these challenges, MoMaGen formulates data generation as a constrained optimization problem that satisfies hard constraints (e.g., reachability) while balancing soft constraints (e.g., visibility while navigation). This formulation generalizes across most existing automated data generation approaches and offers a principled foundation for developing future methods. We evaluate on four multi-step bimanual mobile manipulation tasks and find that MoMaGen enables the generation of much more diverse datasets than previous methods. As a result of the dataset diversity, we also show that the data generated by MoMaGen can be used to train successful imitation learning policies using a single source demo.